A deepdive into Large Language Models
Headline 2 - What does Saga do?
Heading 3 - What does Saga do?
Headline 4 - What does Saga do?
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
"Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur."
Ordered list
- Item 1 Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
- Item 2 Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
- Item 3 Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Unordered list
- Bullet 1 ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
- Bullet 2
- ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
- Bullet 3
AI Chat - Ask questions about your documents, draft content, analyze contracts, and run legal research through a natural language conversation. Every answer is cited back to its source.
Bold text
Emphasis
Superscript
Subscript
At the heart of the Generative AI revolution are Large Language Models (LLMs), along with concepts like tokens, transformers, creativity settings (temperature), and more. As these terms have become increasingly common in AI discussions, let’s explore what they mean.
How did LLMs come about?
LLMs, or Large Language Models, are advanced AI systems trained on large datasets of texts (hence the name large language model). These models can generate human-like language, and with the right instructions, facilitate natural conversations. An example of an LLM is GPT4o from OpenAI.
It’s important to note that ChatGPT itself isn’t an LLM but rather the interface software to interact with these models. To use an analogy: OpenAI represents the car manufacturer, ChatGPT functions as the vehicle itself, and models like GPT-4o provide the powerful engine that drives the car.
The foundation for today’s LLMs was established by Google researchers in their revolutionary paper Attention is all you need, which introduced the Transformer architecture in 2017. While it’s rumored that Google had developed similar models internally, OpenAI was the first to effectively implement this architecture in their GPT (Generative Pre-trained Transformer) models – where the “T” stands for Transformer.
So how do you build a Large Language Model based on this Transformer architecture?
The journey to create a Large Language Model begins with massive data collection. Data experts gather enormous amounts of text by downloading substantial portions of the internet and incorporating text from various other sources.
Using this vast training dataset, researchers apply sophisticated machine learning and deep learning techniques to develop a model that excels at predicting words when given a sequence of text. (For an excellent visual explanation of Transformers, visit Transformer Explainer).
This training process is extremely resource-intensive:
- It can extend over several months
- Requires many high-powered GPUs
- Results in what we call “Pre-Trained” models (hence the “P” in “GPT”)
The intensive computational requirements explain why NVIDIA, as a leading GPU manufacturer, has become one of the world’s most valuable companies.
Tokenisation
Computers don’t process language as humans do. To make text comprehensible to machines, words are converted into tokens—numerical representations of words or word fragments. For example:
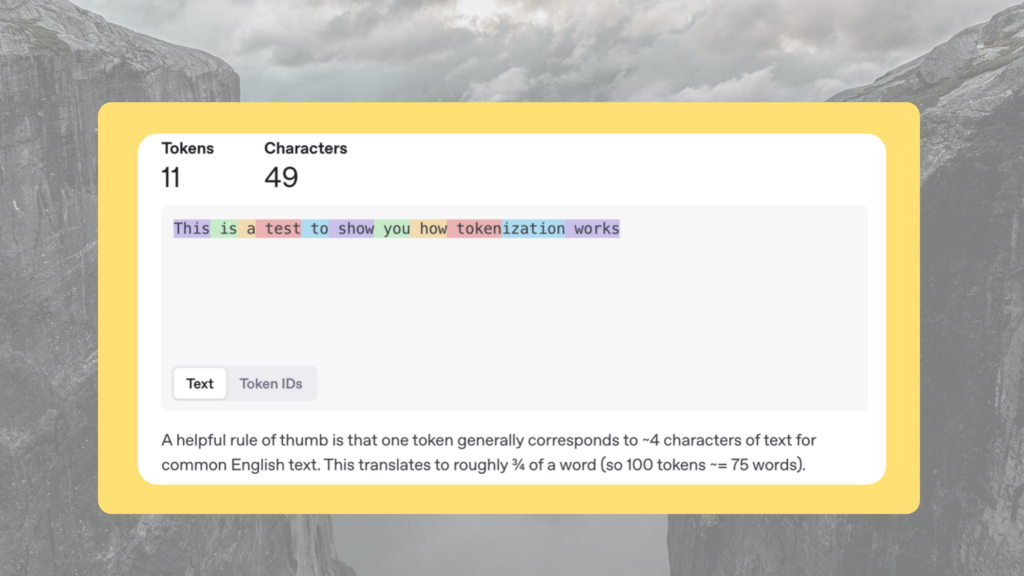
Interestingly, tokenization varies by language, affecting processing costs. English tokens are relatively inexpensive, while languages like Dutch or Norwegian can cost two to three times more to process.
How do LLMs work?
Very practically speaking, these models predict the next word/token based on a certain input (in AI assistants called a prompt). The process works like this:
- The model receives an input text
- It generates a probability distribution of likely next words
- A word is selected from this distribution (based on creativity settings I’ll mention later)
- This chosen word becomes part of the sequence
- The process repeats with the updated sequence
This would look something like this:
As you can see in the video above, each input creates a distribution of the most likely next word.
AI developers introduced a variable called “Temperature” (often referred to as “creativity”) to prevent models from merely reproducing text they’ve been fed during training. This variable essentially changes the probability distribution of the words.
For example, when prompted ‘This is a test to show the readers of this article’:
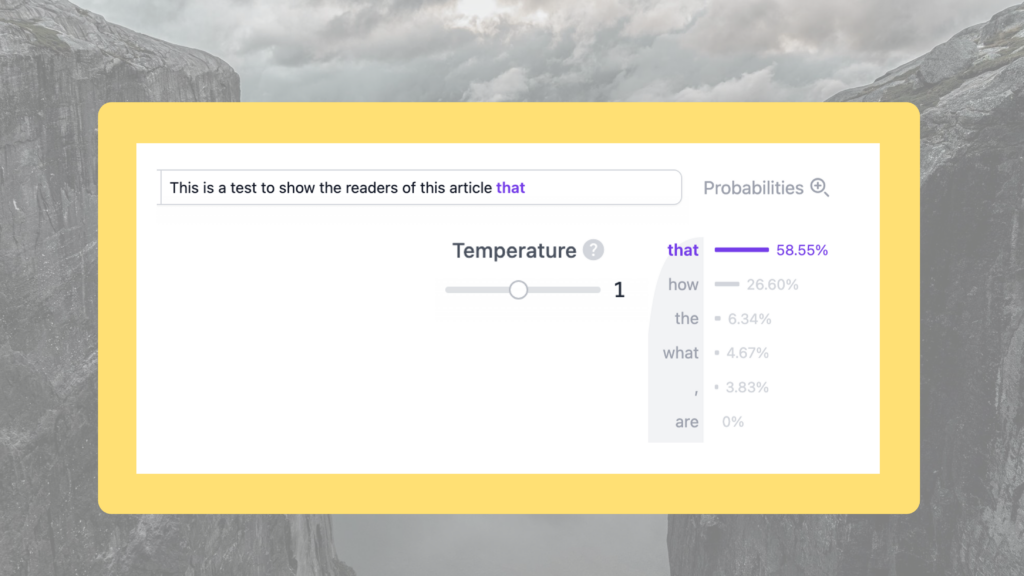
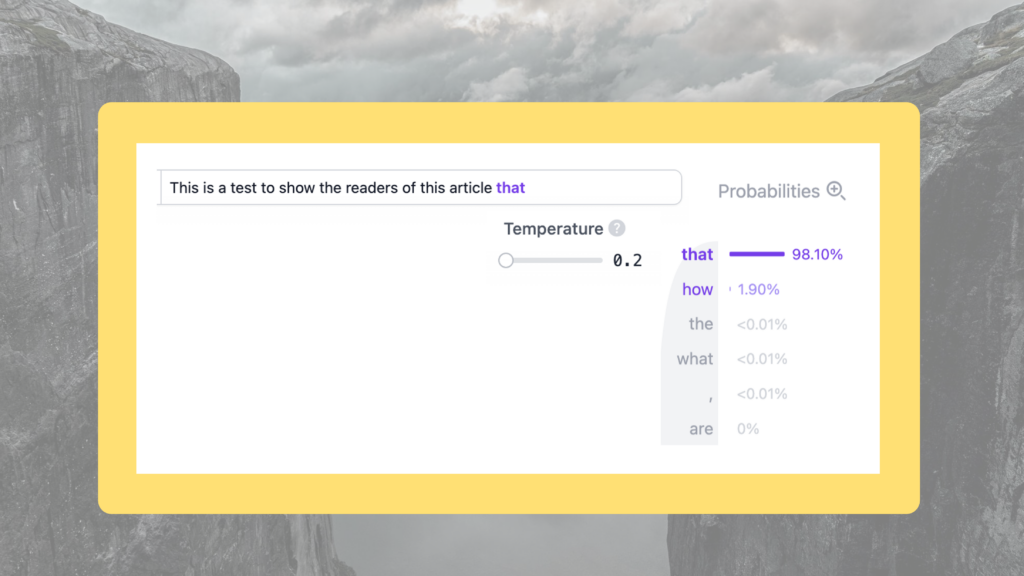
Both scenarios have a different distribution of words from the same input sentence. In both situations the word that is the most likely next word, but in the first scenario, almost 27 out of 100 times, the model will choose the word how instead of that. This explains why AI models provide varied responses to identical questions—higher temperature settings result in more creative outputs but also increase the likelihood of hallucinations. Therefore, in the legal industry, creativity is usually set to a lower number between 0 and 0.5.
Conclusion
The technical complexity of these models extends far beyond what can be covered here, but we hope this gives you a basic idea of this technology. In future articles, we’ll explore model performance and how they correlate with factors like model size, training data volume, and reasoning capabilities.
